Genome is the vital genetic information of all living beings and being able to decode this genome had been an enduring wish for biologists and geneticists alike. The beginning of the era of genome sequencing to its exceptional growth to present day ‘Next Gen Sequencing technologies’ has been outlined in the following sections in an insightful depiction particularly to apprise the science students with the interesting findings and happenings in this amazingly developing scientific arena.
The Dawn of 20th century witnessed a remarkable scientific feat, The Rediscovery of Mendel, which paved our way towards understanding the pattern of inheritance in living organisms. Although this laid the foundation of modern era genetics, scientists were still sceptical about the exact nature of genetic material. Nonetheless, the quest of unlocking the genetic blueprint instigated scientists to carry out innumerable experiments which provided concrete evidences in support of DNA being the genetic material. The final breakthrough was the discovery of Double helix model of DNA which provided all the plausible answers for the previous assumptions related to the quality and behaviour of genetic material. The Double Helix structure of DNA opened up many more questions for the researchers to ponder upon. The first and the most obvious one was “How the information required for building an organism is stored in DNA and how is it decoded? The answer was provided by Marshal Nirenberg and his colleagues in 1960’s when they confirmed that the information is stored in DNA via three letter codes which are a result of non-random combination of four bases A, T, G and C. These letters are four different nucleotides which on forming a triplet, code for their cognate amino acid.
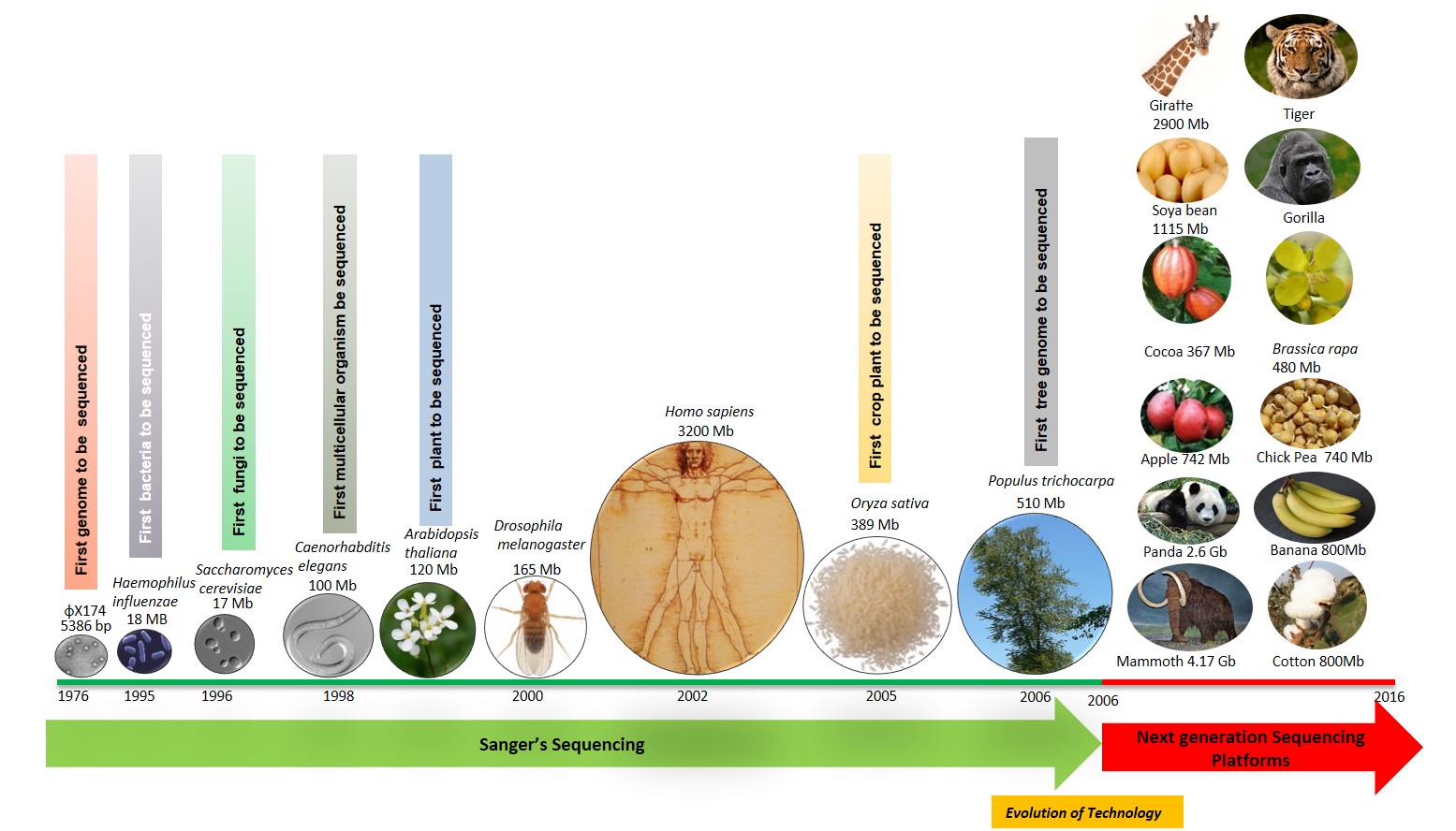
As the bits and pieces of the story of DNA was being assembled scientific pursuit gained momentum towards unlocking the complete genetic blueprint of organisms, so that it can be made accessible to mankind for harnessing its true potential. This mammoth task could be envisioned because of the discovery of a facile DNA sequencing technology popularly known as Sanger’s sequencing, named after its inventor Frederick Sanger. For over three decades, with many structural refinements and mechanical automations this landmark technology has become a routine in molecular biology labs. Later on, in first half of the 21st century many new high throughput genome sequence technologies were invented that spawned the research in frontier areas of biological sciences. The whole gamut of these technologies was termed as Next Generation Sequencing Technologies (NGS). These NGS platforms can produce massive amount of data in a short period of time and as an outcome presently we have large catalogues of sequenced genomes from diverse life forms. The humungous information that has been generated by worldwide genome sequencing efforts of living organisms has enlightened the mankind with many previously unknown facts and would certainly benefit the generations to come.
The Beginning - What is Genome and how is it sequenced?
Genome as we understand it is the entire set of genes of a living being but by definition it is the “complete set of genetic information in an organism. It provides all the information the organism requires to function”. The genome in essence is all the information needed to build and function an organism, encrypted in the form of long sequences of DNA or RNA. Thus, sequencing whole genomes to decipher the entire sequence of DNA/RNA contained in it was the most fascinating dreams of its time. A revelation which would uncover the most pertinent question of all times “how living systems function”. An effort which was thought to provide answers for almost all questions related origin and establishment of life on this planet.
The first sequencing attempts were made to infer the sequences of relatively simpler and homogenous RNA populations like ribosomal and transfer RNA or ssRNA, genetic material of some bacteriophages. However, the initially used chemical techniques only allowed for the determination of composition of these oligonucleotides and to get these in a proper order was still a challenge. But challenges never impede the progress of science they make way for new ideas to be born and tested and the same happened when Fred Sanger’s group decided to radiolabel the partially digested RNA fragments and separated them using a two-dimensional fractionation method. This novel idea laid the foundation and the coming years were flooded with reports of sequencing various cellular and viral RNA molecules.
Sanger's sequencing has been a most versatile method of DNA sequencing from 1970’s to 2005. For sequencing, four different reaction setups are constituted differing only for the di- deoxy terminator used. During chain progression, the chain is terminated where the di-deoxy terminator binds to its complementary base pair. Each reaction generates products of different sizes. These samples are then electrophoresed and the sequence is revealed by visualizing the autoradiogram. Later on, this technology was automated by use of fluorescent labelled di-deoxy terminators and capillary electrophoresis for running the samples. The merit of this method of sequencing is the increased read length which is around 750 bp. Read length is the size of DNA which can be sequenced in a single run. But, the main limitation of Sanger's sequencing is that it cannot be scaled up for sequencing large genomes. To overcome this limitation various new methods of DNA sequencing are now available. Amongst all Next Generation Sequencing platforms e.g. Illumina sequencing platforms have gained wider popularity amongst the researchers. Illumina sequencing platforms use fluorescent-labelled reversible dideoxy terminators. Once these terminators pair with their complementary base pair the fluorescence is recorded and then the reversible terminating group is removed, the cycle is repeated till the whole stretched is sequenced. In this way, the sequence can be decoded in real time. Although many NGS platforms are now available but all of them have their own caveats. The most important is the read length, only a few of them can attain a higher read length and that too without compromising with the quality and the amount of data generated.
The Milestones- Some Important Genomes
?X174 (1976)
?X174 is a bacteriophage and was the first DNA based genome to be sequenced. It has 5386 bases. Over the years, ?X174 has been explored to gain a status of model phage system.
Haemophilus influenzae (1995)
This was the first bacterial genome to be sequenced. It was sequenced by Craig Venter and his team at The Institute for Genomic Research in Rockville, Maryland, USA. It has 1.8 million bases and a single chromosome.
Saccharomyces cerevisiae (1996)
Popularly known as ‘Baker’s yeast’ is extensively used by researchers for investigating basic questions in biology. It was sequenced by collaborative efforts of 600 scientists under the aegis of The International Yeast Genome Consortium. It has 35 chromosomes and a total of 12.1 million bases. It was interesting to note that the yeast genome carried versions of many human genes.
Caenorhabditis elegans (1998)
C. elegans gained the status of model organism for biological investigation because of its simple anatomy and ease in manipulation. Many initial studies on understanding the nervous system and cellular signalling were undertaken on this nematode. The C. elegans genome sequence consortium sequenced the whole genome in 1998. It has around 100 Million bases and 19,735 protein-coding genes.
Arabidopsis thaliana Genome (2000)
It is commonly known as ‘Thale cress’. Arabidopsis is being extensively used as a model system for understanding the development and behaviour of plants. The genome was sequenced by the ‘The Arabidopsis Genome Initiative’ in 2001. Although being a fully evolved flowering plant its genome is relatively small with a size of 119 Mb coding for around 26,000 genes. The sequence of Arabidopsis genome has provided a concrete framework for modern research in plant biology.
Human Genome (2001)
The human genome project was one of the great marvels of scientific research towards understanding the finest creation of nature; how the genetic blueprint for building a human being looks like. This feat was achieved by The International Human Genome project in 2001. Human Genome size is approximately 3200 Mb and it roughly codes for around 30000 proteins.
Oryza sativa (2005)
Rice is a staple food for millions of people across the globe. Rice is the first sequenced crop genome. The International Rice Genome Sequencing Project (IRGSP) released the rice genome sequence in 2005. This was the first International genome sequencing consortia where India was also a partner. The size of Rice genome is 380 Mb.
Populus trichocarpa (2006)
Popularly known as black cotton wood. This was the first tree genome to be sequenced. More than 45,000 putative protein-coding genes were identified. The genome size is 510 Mb.
Story of our Genome: The Human Genome
“The human genome holds an extraordinary trove of information about human development, physiology, medicine and evolution”
- International Human Genome Sequencing Consortium
The most ambitious undertaking after having completely sequenced few simpler genomes was “The Human Genome Project” which aimed to decode the entire 3 billion DNA bases that make a human. The complete sequence of the 25,000 -30,000 genes in the human race should allow us to better understand its functioning as we aim to make this information medically and clinically relevant. The variability (in the form of Single nucleotide variations) in the various human genomes sequenced so far helps us to put the pieces of this puzzle together as to why some individuals, families or ethnic groups are at more risk for some particular disorder. These disorders as they are genetic or genomic in character result due to some notorious mutation(s) in some vulnerable gene resulting in higher probability towards such diseases. And the sequence information availability will not only identify the high-risk individuals but may also provide better customised treatment for such patients. A brilliant example of an individualised treatment comes from certain patients suffering from metastatic melanoma who have been shown to harbour a mutation in the gene BRAF kinase and display significantly better management of this disease with the drug vemurafenib compared to the individuals without that mutation. In another remarkable example of genome sequencing coming to the rescue of ‘California twins’ who had been diagnosed with a rare genetic disorder in childhood known as dopa-responsive dystonia but later in their life when they started to develop other symptoms doctors could not place them in any known disorder category. But sequencing of the twin’s genome by the “Human Genome Sequencing Centre” at the Baylor College of Medicine discovered a rare mutation in a single gene for “sepiapterin reductase” responsible for production of neurotransmitters. Finally, treatment with the lacking precursors lead to resolution of the symptoms. The personal genome sequence information of individuals may well become a basic proactive diagnostic routine in the future but before we attempt to define the clinical implementation of this information a lot needs to be done.
The human genome sequence when put in evolutionary perspective directed the sequencing of other primate genomes like our closest relatives, ‘Chimpanzees’ and little distant ones like ‘Rhesus Macaques’. The comparison of human genome with other primates highlights the evolutionary route of our species and also unravels the significant similarities and differences between us and our phylogenetic neighbours on the tree of life. This comparison also reveals some interesting information e.g. a fraction of human population harbours a defective gene in their genome, this gene codes for an enzyme which is vital for metabolising the amino acid phenylalanine and thus its lack of functionality leads to a disease known as phenylketonuria. But recently, comparison between the genome sequences of humans and macaques revealed the mutated sequence to be the normal sequence in macaques with no consequential effects. Interestingly, this leads us to the possibility that many of the disease susceptibility genes in humans could actually be the normal ancestral variants.
The Final Words…
The establishment of DNA being the genetic material of life and further decoding the information it contained in the form of assembled nucleotides instigated the scientific community to develop technologies to read through this information and comprehend it. This urge led to the discovery of first the sanger’s sequencing technology and then further refinements leading to the now widely used next generation sequencing technology platforms. Bringing these genome sequencing technologies to understand the genetic composition of various forms of life starting from single celled bacteria to simple multicellular organisms to the most complex life form ‘humans’ provided us with much valuable information about the evolution of living forms. Additionally, the sequencing of human genome has allowed us an opportunity to learn about the functioning of human body and its regulations at molecular level which in time to come shall realise the prospect of ‘genetically tailored’ drugs for individualised treatment regimens. Genome sequencing is proving to be a stepping stone in realization of our quest to explore the unique and exceptional life forms present in nature which shall allow us to understand and appreciate their uniqueness and to learn their secrets from their genetic information.